
Когда в компании назревает обновление инфраструктуры, а параллельно обсуждается, как расти и где размещать команду, в середине первого вопроса нередко появляется мысль купить офис — и вот здесь опыт выбора хостинг‑провайдера неожиданно выручает. Ещё во времена, когда здесь разбирали, как работают провайдеры и чем они отличаются, стало понятно: устойчивость сервисов складывается из десятков мелочей, и каждая из них проверяется списком конкретных вопросов без красивых обещаний.
Что действительно важно при выборе хостинг‑провайдера
Критерии выбора просты: стабильность площадки, прозрачные условия поддержки, предсказуемые расходы, безопасность и удобная миграция. Всё остальное — вариации вокруг этих пяти опор.

Проверка начинается не с прайсов, а с понимания нагрузки: сколько запросов в секунду выдерживает продукт в пике, где пользователи, какие требования к задержкам и доступности. Дальше — инфраструктура провайдера: уровень дата‑центров, резервирование, узлы обмена трафиком, магистрали. Важен и человеческий фактор: как работает первая линия, сколько времени занимает эскалация, что происходит ночью и в праздники. Финансовая сторона — не про «дёшево», а про полную стоимость владения за год‑два: ресурсы, трафик, бэкапы, лицензии, поддержка. Наконец, безопасность: соответствие отраслевым требованиям, сертификация, логирование, отчётность. Эти базовые вещи снимают 80 процентов будущих проблем ещё до подписания договора, и, между прочим, так же выбирают и физические площадки под офис, где инфраструктура здания и окрестные магистрали влияют на стабильность не меньше, чем железо.
Ключевые типы хостинга: как понять, что подойдёт вашему проекту
Тип платформы определяет бюджет и гибкость: виртуальный хостинг подходит для стартов, виртуальные машины — для малого и среднего трафика, выделенные серверы и контейнеры — для предсказуемой высокой нагрузки, управляемые платформы — для ускорения командной работы.
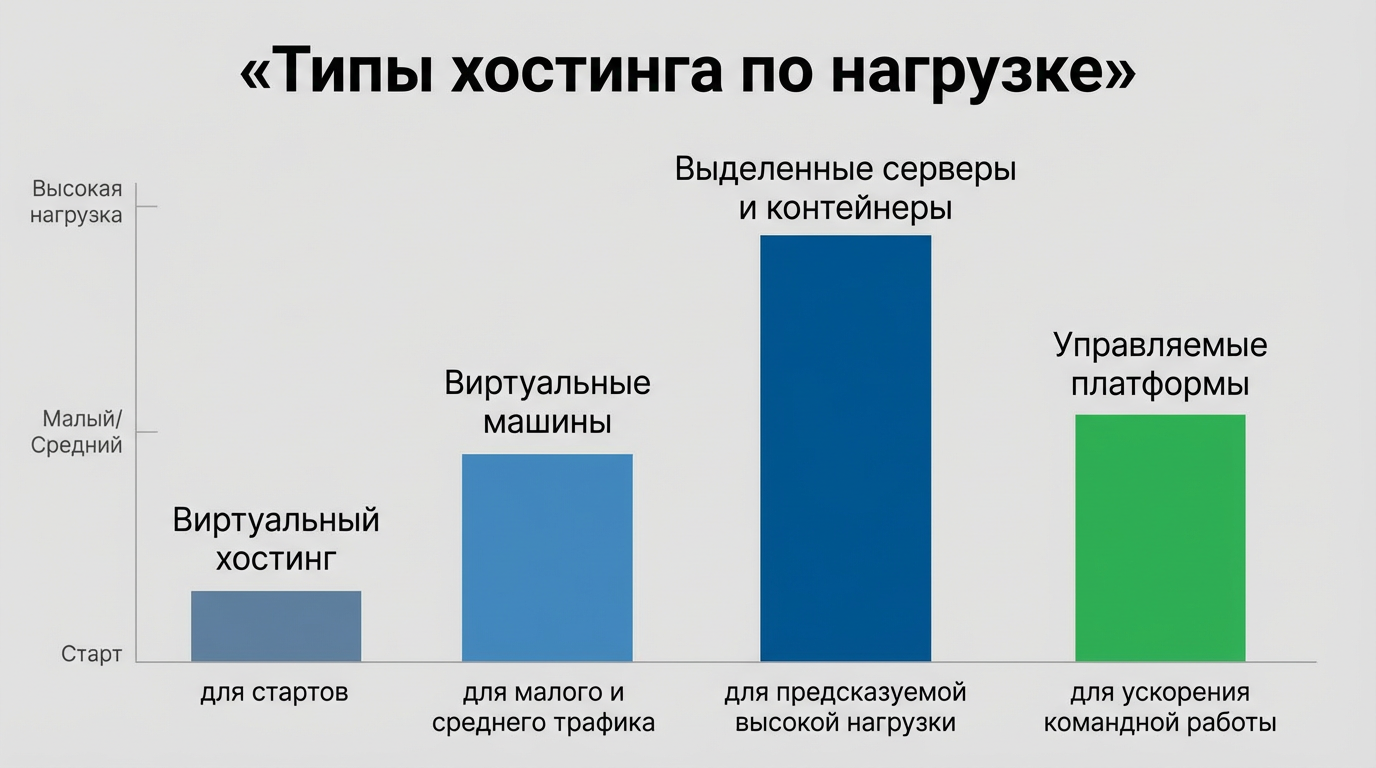
Чтобы не промахнуться, лучше сопоставить профиль нагрузки и зрелость команды. Если нет штатного администратора, управляемые решения часто оказываются выгоднее — меньше простоя и ручной рутины. Для проектов с распиленной архитектурой подходят контейнеры и оркестраторы. Если нужна пиковая производительность под базы, смотрят на выделенные сервера и быстрые твердотельные накопители (SSD) с гарантированной IOPS. Для непредсказуемых рывков полезны авто‑масштабирование и оплата по факту. Ниже — удобная сводка по выбору.
| Сценарий | Тип платформы | Плюсы | Риски |
|---|---|---|---|
| Лендинг, корпоративный сайт | Виртуальный хостинг | Дёшево, просто стартовать | Ограничения по нагрузке, соседние проекты влияют |
| Интернет‑магазин до 1 тыс. одновременных пользователей | Виртуальные машины | Гибкие ресурсы, изоляция | Нужны навыки администрирования |
| Высоконагруженная база данных | Выделенный сервер | Предсказуемая производительность | Медленное масштабирование, управление на вас |
| Микросервисы, CI/CD | Контейнеры и оркестрация | Быстрая доставка, плотная упаковка | Сложность стеков и мониторинга |
| Мобильное приложение с всплесками | Управляемая платформа | Авто‑масштабирование, меньше рутины | Привязка к провайдеру, стоимость за комфорт |
Проверка надёжности: инфраструктура, дата‑центры и география
Надёжность видна по инженерии: уровни резервирования, питание, охлаждение, магистрали, независимые провайдеры связи и аварийные процедуры. География узлов влияет на задержки и юридические требования.
Сначала про дата‑центры. Запрашивают схему питания: две независимые линии, ИБП и дизель‑генераторы. Смотрят на архитектуру охлаждения, температурные коридоры и датчики. Из физической безопасности — контроль доступа, видеонаблюдение, журнал посещений. По сети важны резервные выходы в разные точки обмена трафиком и наличие фильтрации распределённой атаки отказа в обслуживании (DDoS) у периметра. География диктует приватность данных и соответствие местным законам: для персональных данных россиян хранение и обработка осуществляются в пределах РФ, а это лучше подтвердить документально ссылкой на площадки. Полезно попросить отчёты по инцидентам за год, пусть обезличенные, и план учений по авариям: это показывает зрелость процессов. В идеале нужен тестовый доступ к узлам, чтобы замерить задержки из реальных регионов, где живут пользователи.
Соглашение об уровне сервиса: что обязательно проверить в тексте договора
Сначала ищут численные метрики: доступность, время реакции, время восстановления и штрафы. Затем — исключения и порядок расчёта простоев. Наконец — как подтверждаются события и кем.
Соглашение об уровне сервиса (SLA) — не про красивые проценты, а про измерение и ответственность. Если написано «доступность 99,95», нужно понимать окно наблюдения, включены ли в расчёт плановые работы, как считается период недоступности и как подтверждается инцидент. Время первой реакции — минуты, а восстановления — часы. Бывает, что реакции обещают быстро, а на деле исправления затягиваются из‑за отсутствия эскалации. Проверьте, какие каналы обращения учитываются в метриках: тикеты, почта, телефон. Штрафы должны быть автоматическими, без «по письменному заявлению в срок не позднее». Ниже — короткая таблица, что сверять.
| Параметр | Что спросить | Частая ловушка |
|---|---|---|
| Доступность | Окно расчёта, исключения | Исключают всё подряд, остаётся «почти всегда» |
| Реакция | Минуты по каналам и уровням | Телефон не учитывается в SLA |
| Восстановление | Часы до устранения причины | Нет жёстких сроков после эскалации |
| Плановые работы | Когда и как предупреждают | Ночные окна каждую неделю без выбора |
| Штрафы | Автоматически или по заявлению | Компенсации завязаны на будущие платежи |
Безопасность и соответствие: персональные данные, отраслевые требования
Порядок прост: зафиксировать тип обрабатываемых данных, сопоставить с нормами и проверить у провайдера процессы и доказательства соответствия. Без этого риск штрафов и простоев неприемлем.
Если продукт работает с персональными данными, полезно оформить перечень категорий и целей обработки, и дальше соотнести их с правилами хранения и доступа. У провайдера спрашивают, где физически расположены сервера, кто имеет доступ и как он журналируется. Важны планы реагирования на инциденты, регулярные проверки уязвимостей и обновления. Для защиты каналов используют виртуальную частную сеть (VPN) и шифрование в покое. Для дополнительных требований отрасли сверяют наличие сертификатов и регламентов у подрядчика. Сами тексты нормативов и разъяснений удобнее смотреть через официальный источник: например, разъяснения по персональным данным доступны на сайт rkn.gov.ru, материалы по безопасности инфраструктуры — на сайт fstec.ru, цифровая повестка и инициативы — на сайт digital.gov.ru. Ссылки открывают не для галочки: по ним проверяют актуальные формулировки и сроки обновлений, чтобы договор с провайдером не отстал от реальности.
Производительность: как выбрать железо, накопители и сеть под свои запросы
Стабильная производительность — это правильные процессоры, быстрые накопители, прогнозируемая сеть и кэширование. Главное — тесты на своём профиле нагрузки, а не общие бенчмарки.
Начинают с профилирования: где бутылочное горлышко — процессор, память, диск или сеть. Если критична работа с базой, смотрят на быстрые твердотельные накопители (SSD) с гарантированной производительностью по случайным чтениям и записям. Для высоких нагрузок уместны опции закрепления ресурсов за виртуальными машинами. Сеть оценивают по пропускной способности, задержкам и доступности приватных межузловых каналов. Не забывают про кэширование на уровне приложения и про распределённую память. Сторонние «попугаи» редко помогают, а собственный нагрузочный профиль из реальных запросов показывает картину лучше: запускают тест, фиксируют метрики, повторяют после тюнинга. Такой цикл приносит результат даже командам без глубокого опыта администрирования.
Поддержка и эксплуатация: регламенты, мониторинг и эскалации
Надёжная поддержка понятна по трём вещам: прозрачный регламент, доступ к мониторингу и отлаженная эскалация. Проверяют их на пилотном периоде, а не на словах.
Хорошая первая линия умеет быстро триежить обращения и не боится передавать дальше. Отдельно ценится доступ к метрикам платформы: нагрузка на диск, сеть, задержки, графики аварийных событий. Эскалация — не про «написали менеджеру», а про формальный путь с указанием времени перехода между уровнями поддержки. Полезно попросить шаблоны отчётов по инцидентам и стендап‑выписки после крупных сбоев. Важно договориться о каналах: тикеты, почта, телефон, мессенджеры — и о времени реакции для каждого. Небольшой, но ценный тест: договориться о регламентном окне и посмотреть, как провайдер планирует работы и предупреждает клиентов заранее. По тону общения многое понятно уже на первом же изменении конфигурации.
Финансовая модель владения: как посчитать честную стоимость и не переплатить
Считать выгодно не по месяцу, а по горизонту в 12–24 месяца: ресурсы, трафик, хранение бэкапов, лицензии, простои и поддержка. Это и есть полная стоимость владения.
Базовый тариф — вершина айсберга. В расчёт включают хранилища резервных копий с нужным сроком хранения, исходящий трафик, стоимость выделенных IP‑адресов, лицензий баз данных и панелей управления. Важно учесть простои: даже пару часов в год можно перевести в деньги через потерянные заказы или SLA‑штрафы от ваших клиентов. Отдельной строкой идут миграция и время специалистов. Чтобы разложить модель, удобно завести таблицу в три колонки: обязательные расходы, вероятные расходы и редкие, но дорогие. Так видно, где спрятаны лишние проценты. Финансовые и налоговые детали лучше перепроверять официально, ориентируясь на актуальные положения по НДС и вычетам через сайт nalog.gov.ru: там же бывают ответы на типовые вопросы по документам и актам выполненных работ.
Миграция без простоя: пошаговый план переноса проектов
Рабочий перенос строится так: пилот на копии, параллельный прогон, переключение трафика, откатный план и пост‑анализ. Детали решают всё.
План начинается с инвентаризации: список сервисов, зависимости, данные и точки отказа. Готовят тестовую среду, поднимают копии и запускают нагрузку с реальным профилем. Затем настраивают репликацию данных, чтобы разница между старой и новой площадкой была минимальной к моменту переключения. Для переключения трафика заранее готовят низкие TTL в зоне домена и скрипты на случай быстрого возврата.
Обязательно записывают план отката: какие кнопки нажимают и кто отвечает за каждую. После переключения делают пост‑анализ: какие метрики изменились, где узкие места. Такой же подход, кстати, используют при переездах в новый офис: пилотные тесты каналов связи, «ночное» окно переноса и проверка рабочих мест утром, чтобы команда не теряла ритм.
Масштабирование: горизонтальный рост, балансировка и доставка контента
Надёжное масштабирование держится на трёх китах: статeless‑сервисы, балансировщики и доставка контента ближе к пользователю. Важно уметь добавлять и убирать мощности без ручной сборки.
Для горизонтального роста сервисы проектируют без сохранения состояния, а сессии выносят в общее хранилище. Балансировщики распределяют трафик и следят за здоровьем узлов, а авто‑масштабирование добавляет инстансы при всплесках. Там, где критичны картинки, видео и статические файлы, помогает сеть доставки контента (CDN): точки присутствия снижают задержки и разгружают исходные серверы. Не забывают про кэш на уровне браузера и заголовки. Экономика тоже улучшается: меньше исходящего трафика с бэкенда и короче пики на центральных узлах. Но лучше держать измерения в порядке и проверять, где масштабирование действительно нужно, а где проблему можно решить простым кэшем или оптимизацией запросов.
Своя серверная, колокация или облако: что выбрать бизнесу и как это связано с офисом
Выбор между своей серверной, колокацией в дата‑центре и облаком — вопрос компромиссов: контроль и капитальные расходы против гибкости и скорости. Привязка к офису меняет уравнение.
Если команда планирует расширение и обсуждает, не пора ли «своё железо», решение стоит смотреть вместе с вопросом пространства. В купленном офисе кажется логичным выделить комнату для серверов, но инженерия здания часто не тянет требования к питанию, охлаждению и связи. Колокация в профильном дата‑центре обеспечивает физическую безопасность и магистрали, а облако даёт скорость и масштабируемость без капитальных вложений. Реальный расклад обычно гибридный: критичные базы на выделенных ресурсах и в колокации, вычисления и фронтенд в облаке, а в самом офисе остаются только сетевые узлы и кэш‑проxies. Ниже — компактное сравнение трёх стратегий.
| Вариант | Когда оправдан | Плюсы | Минусы |
|---|---|---|---|
| Своя серверная в офисе | Особые требования к данным, небольшой масштаб | Полный контроль, близость к команде | Дорогое питание и охлаждение, риски с каналами и авариями |
| Колокация | Предсказуемая высокая нагрузка | Инженерия дата‑центра, безопасность, магистрали | Капвложения в железо, логистика |
| Облако | Быстрый рост и переменная нагрузка | Гибкость, запуск за часы, меньше рутины | Зависимость от провайдера, стоимость на долгом горизонте |
Тут снова всплывает ранняя мысль про расширение площадей для команды: идея «купить офис» соблазняет контролем, но для инфраструктуры продакшна чаще выигрывает дата‑центр и облако, а в самой локации остаётся лишь то, что действительно нужно в помещении — переговорные, тест‑стенды, сети доступа. И это нормально: физическое пространство работает на людей, а сервисы лучше живут там, где им безопасно и холодно.
Чек‑лист проверки провайдера: вопросы на первой встрече
Готовый список экономит часы: задайте вопросы по инженерии, поддержке, безопасности и финансам. Попросите документы и доступ к пилоту.
- Площадки и инженерия: резервирование питания и охлаждения, независимые каналы связи.
- Сети: пропускная способность, точки обмена трафиком, фильтрация атак распределённого отказа в обслуживании.
- Безопасность: контроль доступа, журналы, планы реагирования, аттестации.
- Поддержка: время реакции и восстановления, эскалации, отчёты по инцидентам.
- Финансы: что включено в тарифы, как учитываются бэкапы и трафик, как оформляются акты.
- Миграция: пилот, слоты для плановых работ, сценарий отката.
- Юридические вопросы: где хранятся данные, какие исключения в договоре.
Если на любой из пунктов ответ звучит размыто, просите примеры документов и процедуры. Прозрачные команды охотно делятся регламентами и не боятся пилота, где всё станет видно за неделю.
Юридические нюансы: договор, акты, налоги и санкционные риски
Смотрят три вещи: кто и как оказывает услуги, как оформляют документы и какие риски учтены. Это экономит время бухгалтерии и снижает споры.
В договоре важно определить предмет чётко: какие ресурсы, какие уровни сервиса, как считаются периоды обслуживания. Приложения с регламентами и техническими параметрами — часть договора, без них легко упустить детали. Обсуждают порядок и сроки выставления актов, форматы электронного документооборота, полномочия подписантов. По налогам и ставкам сверяются с актуальными публикациями на сайт nalog.gov.ru, а если есть внешнеэкономические риски, то полезно отслеживать официальные разъяснения профильных ведомств через сайт digital.gov.ru. В случае хранения и обработки персональных данных ориентируются на разъяснения регулятора и практику проверок, доступную на сайт rkn.gov.ru. Юридическая рутина скучна, но именно она держит сервис в порядке, когда случается форс‑мажор.
Типовые ошибки при выборе платформы и как их предотвратить
Чаще всего ошибаются в трёх местах: недооценивают нагрузку, игнорируют регламенты поддержки и не считают полную стоимость. Противоядие — пилот, чек‑лист и честная модель владения.
Недооценка трафика приводит к «затыкам» в часы пик и к нервным переключениям в спешке. Игнорирование поддержки оборачивается долгими простоями в праздники: всё сломалось, а «дежурный» отвечает через полдня. Расчёт «по ценнику» не учитывает бэкапы и трафик, а потом удивляет двойными счетами. Из более редких промахов — привязка к экзотическому стеку без команды и попытка утащить продакшн в офисную серверную без инженерии здания. Все они лечатся одинаково: честными замерами, документацией и маленькими шагами, которые быстро показывают реальность.
Кейсы и сценарии: как разложить выбор для разных продуктов
Рабочие решения рождаются из контекста: у каждого продукта своя география, пиковые часы, команда и бюджет. Разберём три типичных сценария.
Первый сценарий — интернет‑магазин среднего размера. Архитектура: фронтенд на виртуальных машинах, база на выделенном ресурсе с быстрыми накопителями, доставка контента в регионы через периферийные узлы. Миграция через тестовую копию и переключение DNS ночью. Второй сценарий — медиа и контент с высокими пиками в прайм‑тайм. Важны балансировщики и кэши, агрессивная стратегия доставки контента, продуманная сеть. Третий — исследовательский стартап с моделями искусственного интеллекта: тут ключевы вычисления, быстрые накопители и доступ к видеокартам на время экспериментов. В каждом случае выбор диктует профиль нагрузки и график развития, а не абстрактные «лучшие практики». И да, когда команда растёт и думает о пространстве, уместно одновременно смотреть и локации для работы, и инфраструктуру для сервисов: офис решает про людей, дата‑центры и облака — про устойчивость.
Готовый план действий на 30 дней: от запроса до пилота и решения
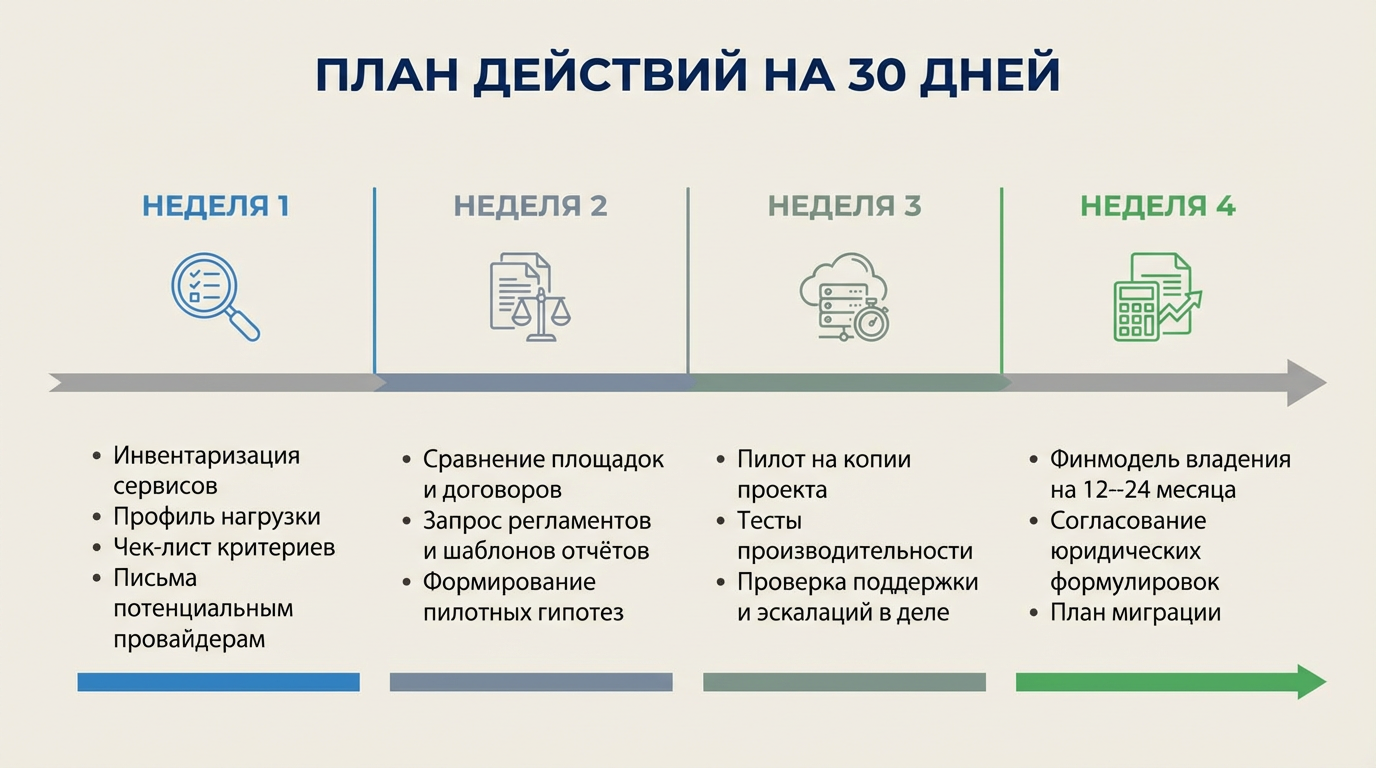
За месяц реально пройти путь от «надо выбрать провайдера» до внятного решения: пять спринтов по неделе закрывают риски и дают цифры.
- Неделя 1: инвентаризация сервисов, профиль нагрузки, чек‑лист критериев и письма потенциальным провайдерам.
- Неделя 2: сравнение площадок и договоров, запрос регламентов и шаблонов отчётов, формирование пилотных гипотез.
- Неделя 3: пилот на копии проекта, тесты производительности, проверка поддержки и эскалаций в деле.
- Неделя 4: финмодель владения на 12–24 месяца, согласование юридических формулировок и план миграции.
- Промежуточные точки: демо‑сессии с командами провайдеров, короткие ретро по рискам, фиксация выводов в одной таблице.
Лайфхаки для успеха: держите все ответы провайдеров в едином шаблоне, чтобы сравнение было честным; включайте в пилот реальные данные и сценарии; заранее договоритесь о «ночном» окне, где безопасно ломать и чинить. Такой подход одинаково помогает и при выборе площадки, и при организационных решениях про пространство — проще говорить фактами.
Мини‑FAQ: короткие ответы на частые вопросы
Несколько быстрых ответов экономят время: это краткие подсказки по граблям, на которые чаще всего наступают.
- Нужен ли отдельный фильтр распределённого отказа в обслуживании: если бизнес‑критичный трафик приходит из открытого интернета, лучше иметь фильтрацию у периметра провайдера и собственные правила на балансировщиках.
- Как понять, что поддержка справится ночью: попросить статистику обращений по часам и проверить пилотом в ночное окно.
- Достаточно ли виртуального хостинга для корпоративного сайта: да, если нет интеграций и всплесков; иначе берите виртуальную машину с запасом.
- Где хранить резервные копии: отдельно от основной площадки, с периодическими тестами восстановления и неизменяемыми снапшотами.
Контрольный список перед подписанием договора
Пройдитесь по десяти пунктам: если на все «да», можно двигаться дальше. Этот список закрывает основные риски.
- Профиль нагрузки и пиков подтверждён замерами.
- Площадки и инженерия проверены документами.
- Метрики соглашения об уровне сервиса расписаны и измеримы.
- Регламенты поддержки и эскалаций приложены к договору.
- Пилотный перенос прошёл и результаты зафиксированы.
- Безопасность и хранение данных соответствуют требованиям.
- Финмодель владения составлена на 12–24 месяца.
- Процедуры резервного копирования и восстановления согласованы.
- Юридические формулировки и порядок актов утверждены.
- План отката и контакты ответственных подтверждены.
Если хотя бы по двум пунктам сомнения, лучше продлить пилот или посмотреть альтернативы. Быстрая пауза сегодня экономит месяцы завтра.
Куда смотреть за обновлениями и проверенными разъяснениями
Лучшие источники — официальные площадки: там публикуют разъяснения и документы. Сохраните их в закладки.
- сайт rkn.gov.ru: разъяснения по персональным данным и проверкам.
- сайт digital.gov.ru: цифровая повестка, проекты и инициативы.
- сайт nalog.gov.ru: налоги, НДС, электронный документооборот.
Проверяйте даты публикаций и версии документов: даже мелкая правка меняет трактовку обязательств. Ссылки нужны не для вида, а чтобы быстро вернуться и перепроверить формулировки перед подписанием.
Заключение: как принять взвешенное решение и не пожалеть через год
Сильный выбор держится на дисциплине: сначала понять свою нагрузку, потом оценить инфраструктуру и людей у провайдера, посчитать честную стоимость и подтвердить всё пилотом. Этот маршрут скучнее, чем красивая презентация, зато спустя год сервис стабилен, команда спокойна, а бюджет предсказуем.
Если на горизонте параллельно обсуждается рост штата и идея расширить пространство или даже «купить офис», решение по инфраструктуре и решению для людей лучше принимать в одной логике: продакшн — там, где безопасно и холодно, а команда — там, где светло и удобно работать. Такой расклад объединяет обе темы в одну здравую стратегию: сервисы не падают, сотрудники не мёрзнут, бизнес не платит дважды.
Сделайте шаг сейчас: соберите профиль нагрузки за неделю, запросите регламенты у трёх провайдеров и назначьте пилот. Дальше будет проще. Каждый следующий день добавляет ясности и уменьшает риски — это тот редкий случай, когда маленькие шаги работают быстрее больших заявлений.